Ollama + OpenClaw 快速上手|macOS 篇
macOS 專用教學:用 Ollama 免費雲端額度,幾分鐘內讓 OpenClaw 開口說話,完全不用設定 API Key。

<img src="/images/dock_head_s.png" alt="鴨編" width="24" style="vertical-align: middle;">鴨編快說重點:Ollama + OpenClaw 完全不用設定 API Key。用 Ollama 帳號的免費雲端額度,選好模型就能開始對話,整個流程是這樣的:安裝 Ollama → ollama launch openclaw → 選雲端模型 → 開始對話
Step 1:安裝 Ollama
- 前往 ollama.com/download
- 點擊「Download for macOS」
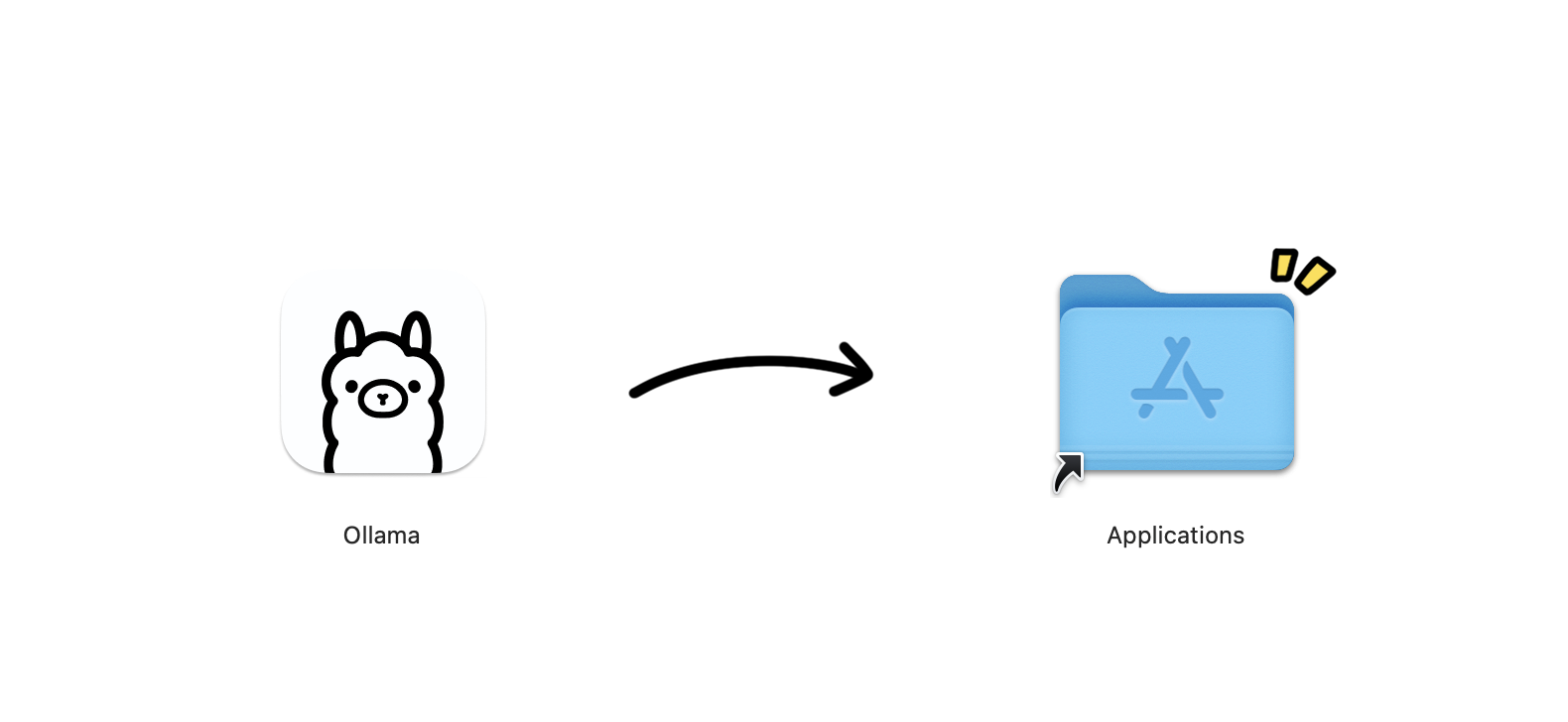
- 打開下載的
.dmg,把 Ollama 拖到「應用程式」資料夾 - 打開 Ollama
🚨 macOS 安全性提示:如果看到「無法打開 Ollama,因為來自未識別的開發者」,到「系統設定 → 隱私與安全性」拉到底點「仍然開啟」。
確認安裝成功:
ollama --version看到版本號就 OK:ollama version 0.6.x
Step 2:一鍵啟動 OpenClaw
開啟終端機:
輸入:
ollama launch openclaw
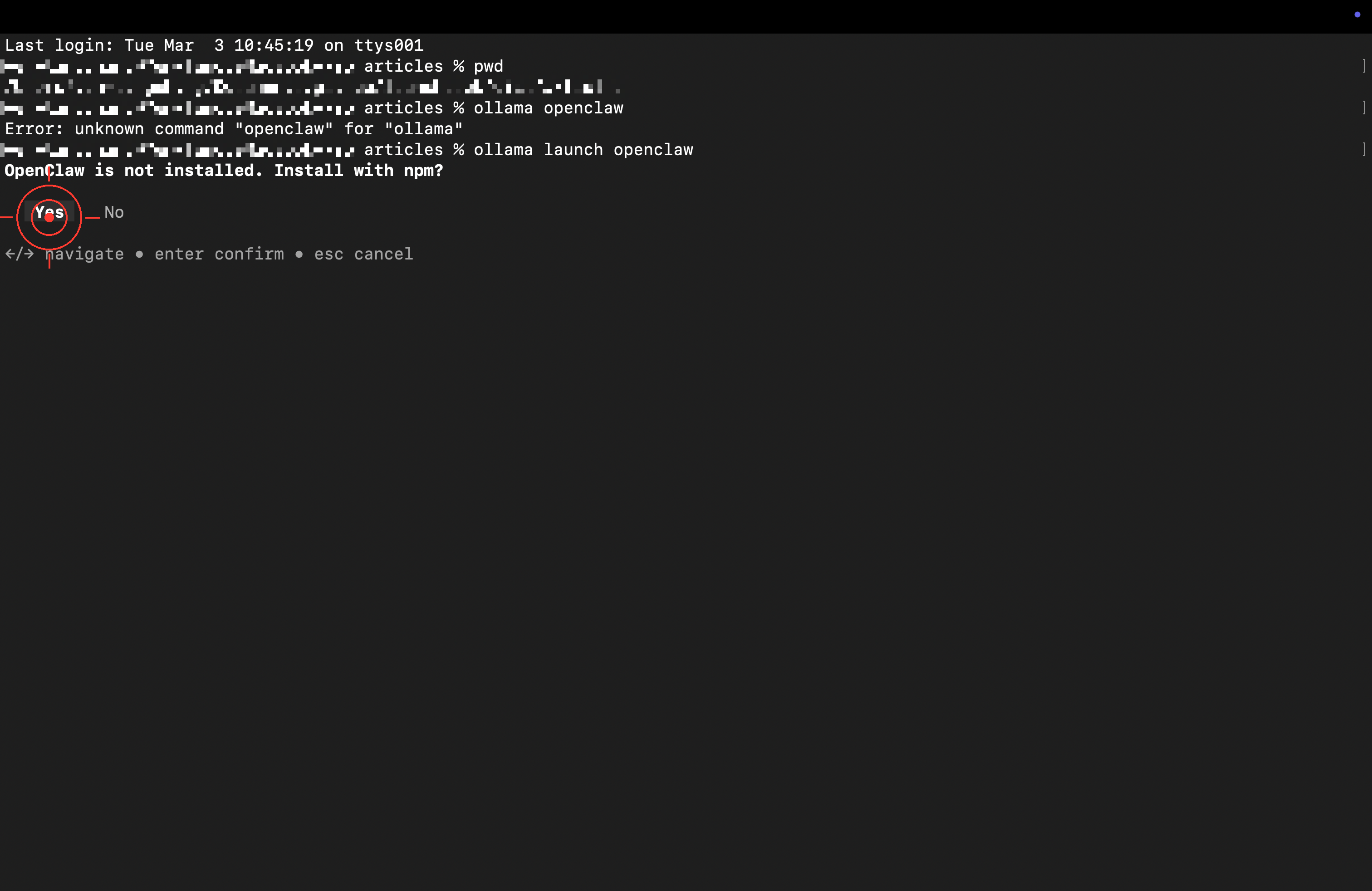
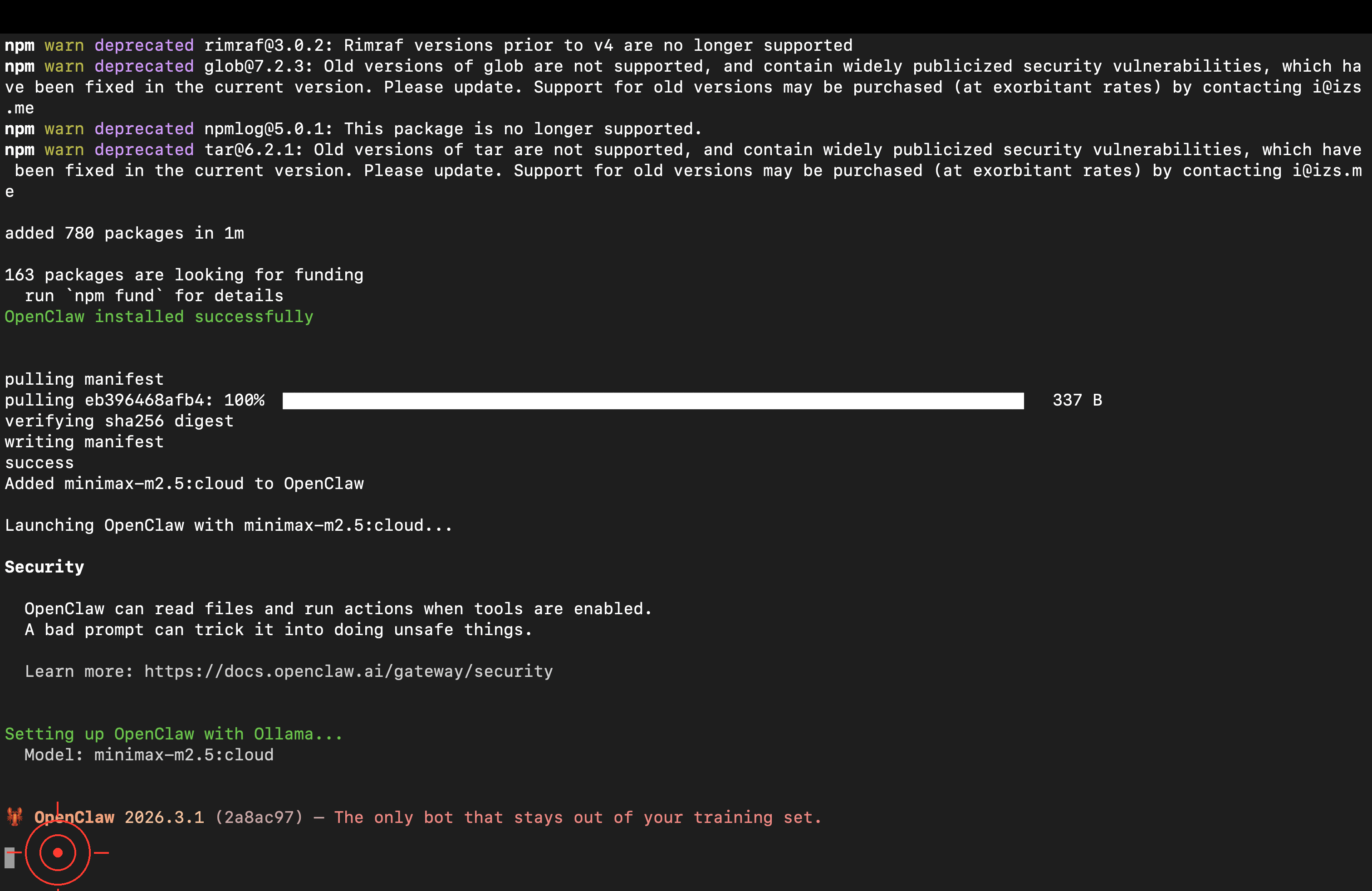
第一次執行會自動安裝,詢問是否用 npm 安裝時按 Enter 確認:
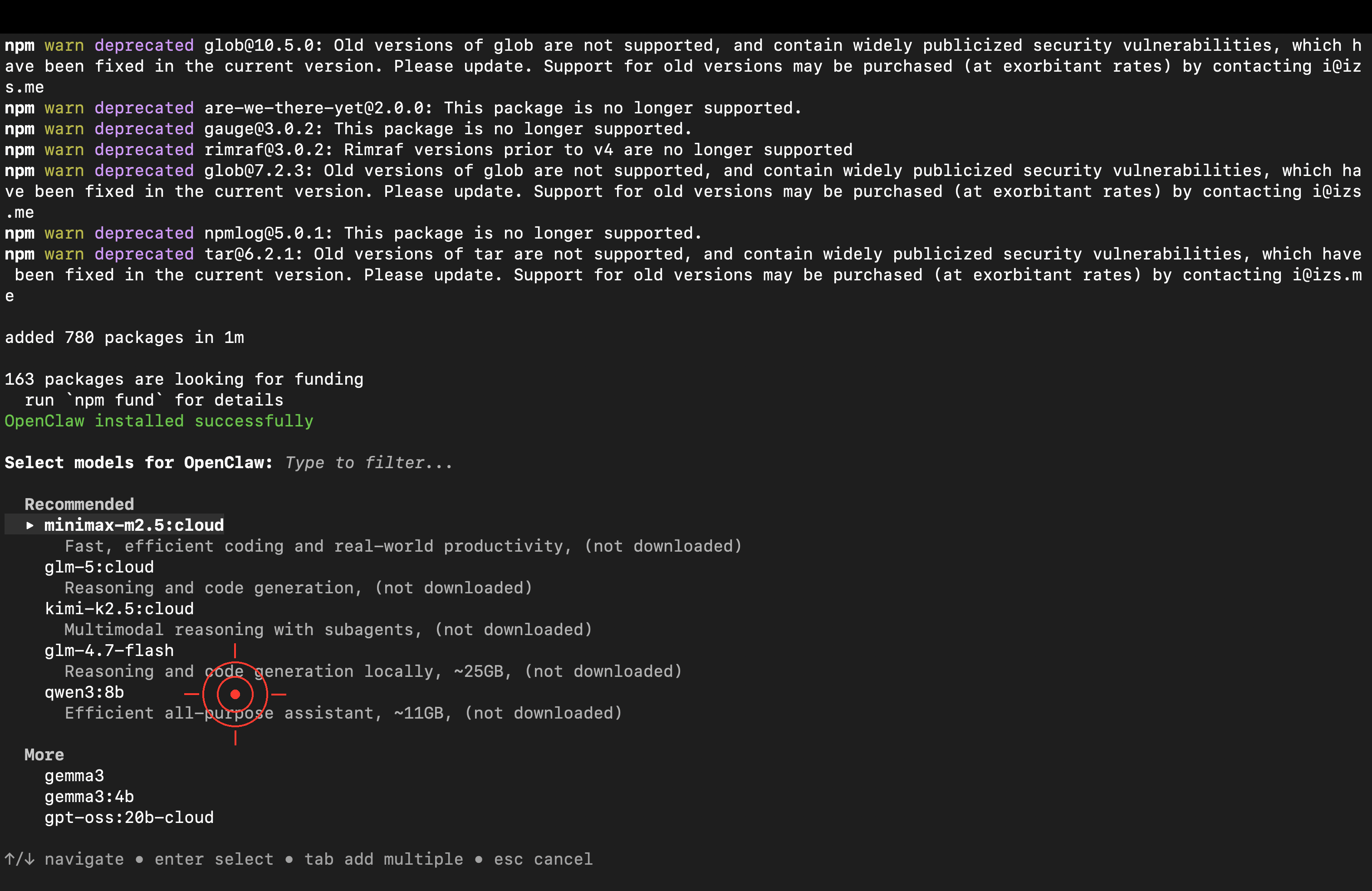
安裝完成後選擇模型,選「Cloud」即可,不需要下載模型到本機。
<img src="/images/dock_head_s.png" alt="鴨編" width="24" style="vertical-align: middle;">推薦的雲端模型(用 Ollama 免費額度,免下載):
模型 特色 minimax-m2.5🥇實測推薦:工具呼叫能力最佳,Agent 任務表現優異 kimi-k2.51T 參數,對話品質強 glm-4.7通用型,穩定可靠 不過要說明的是:以上模型試玩沒問題,但若要正式導入工作流程,還是建議換用 Claude、GPT-4o 等主流模型——穩定性與工具使用的可靠度仍有明顯差距。
macOS 可能跳出安全性提示(Node.js 是 OpenClaw 執行環境),點「允許」即可:
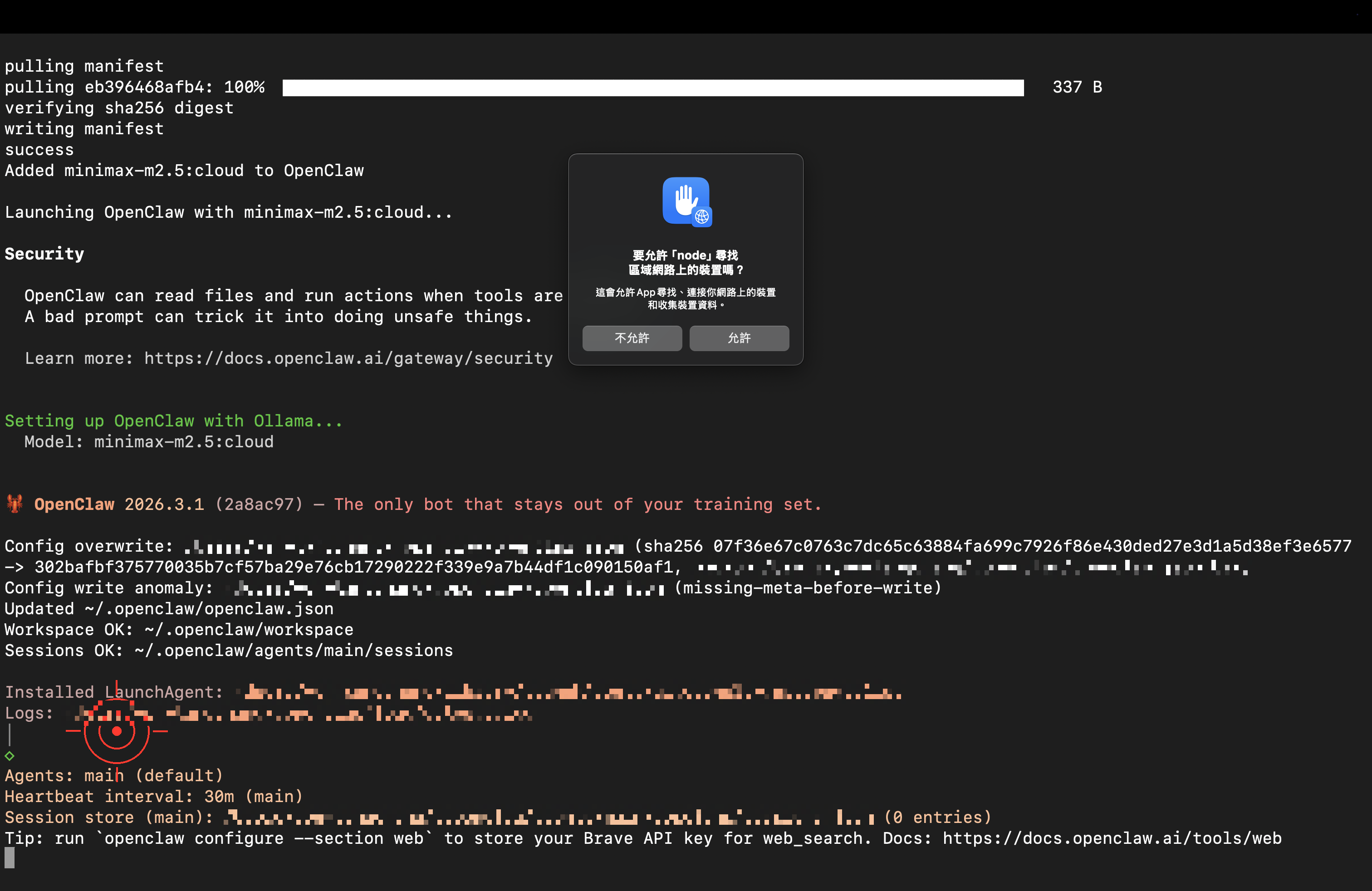
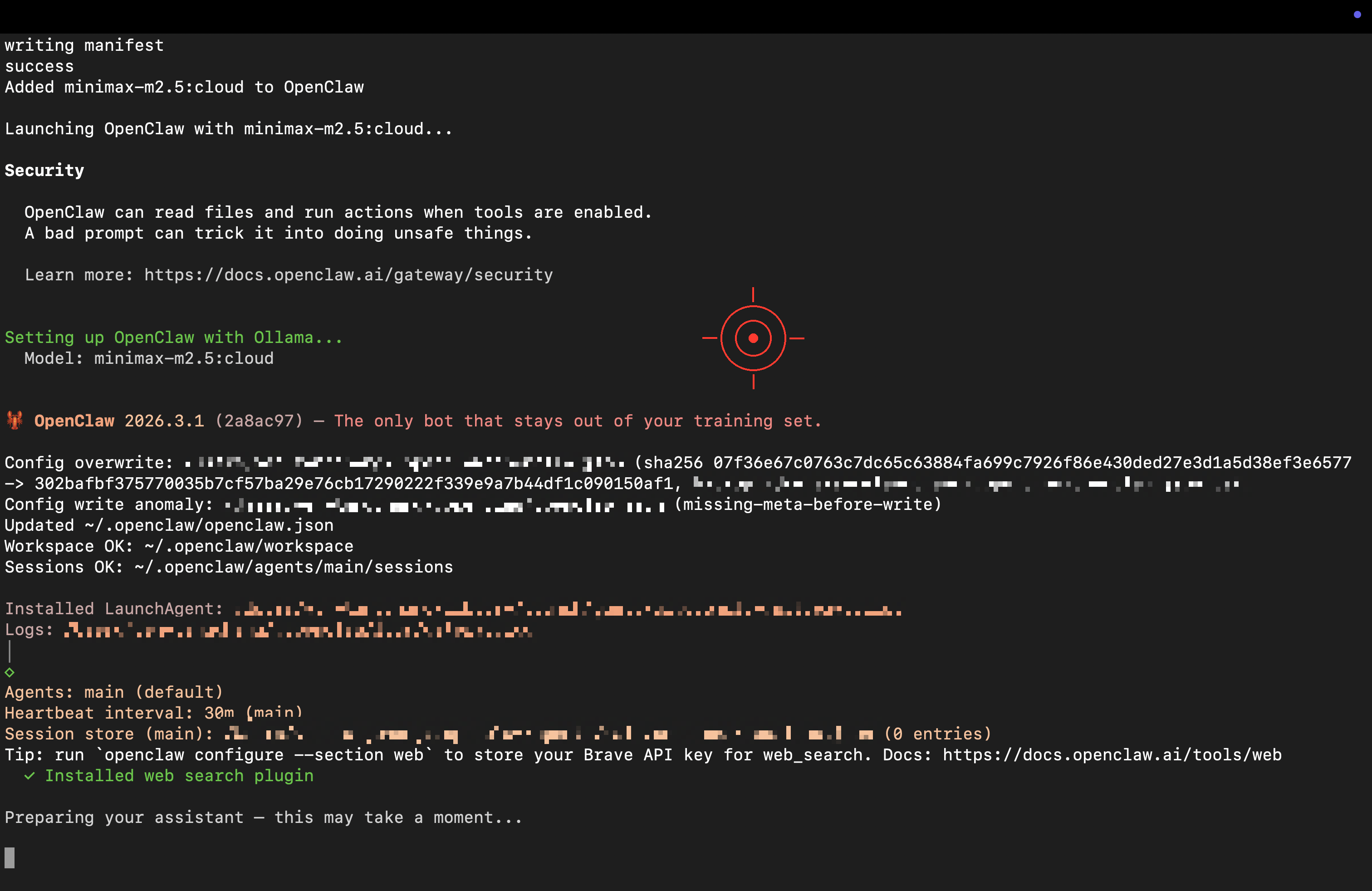
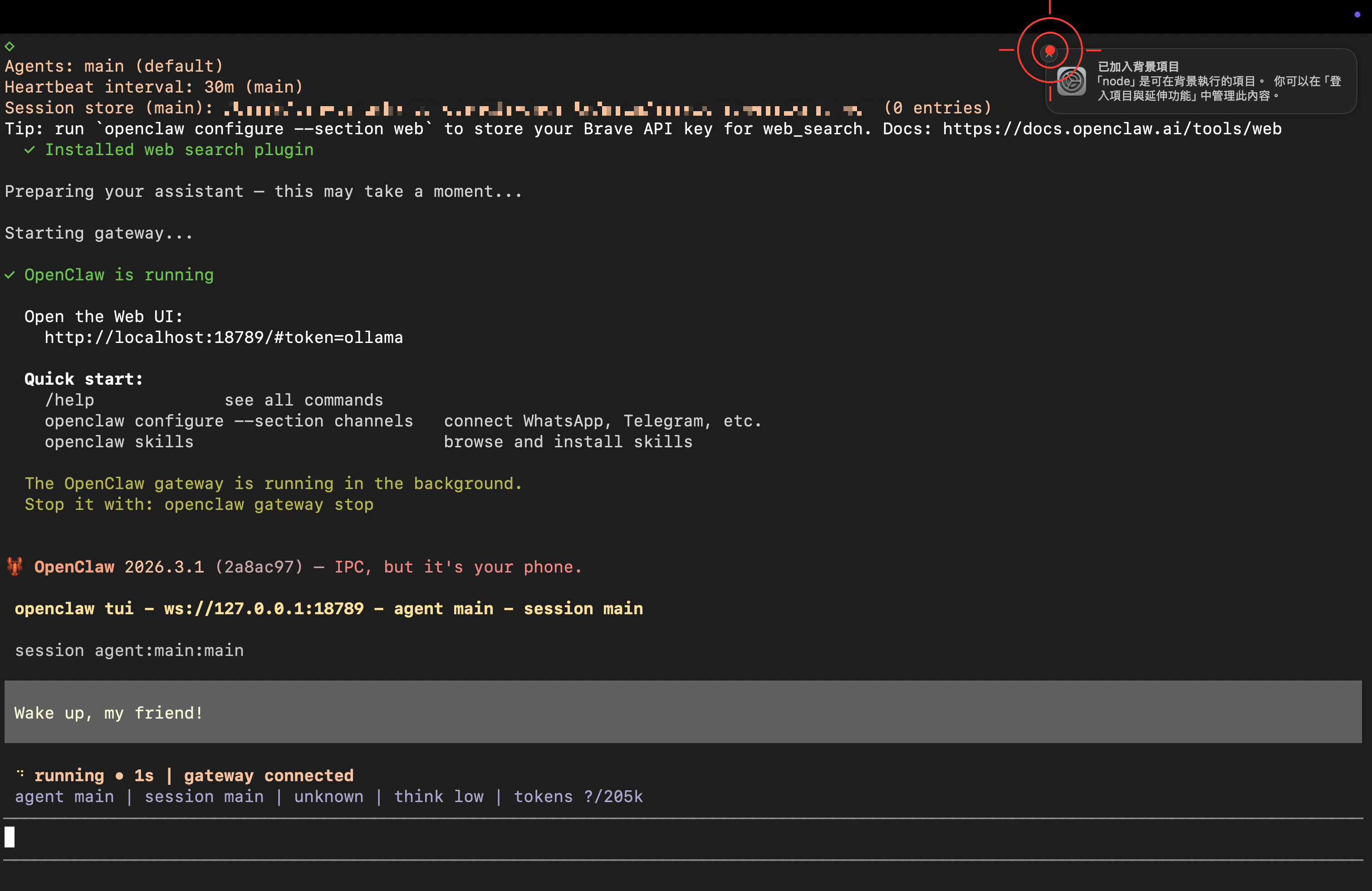
出現就緒畫面,代表成功啟動!
Step 3:第一次對話——幫龍蝦取個名字 🦞
試著輸入:
你好!我是這裡的主人。請用繁體中文自我介紹——你是誰、你能做什麼。
另外,幫你自己取一個有特色的中文名字吧!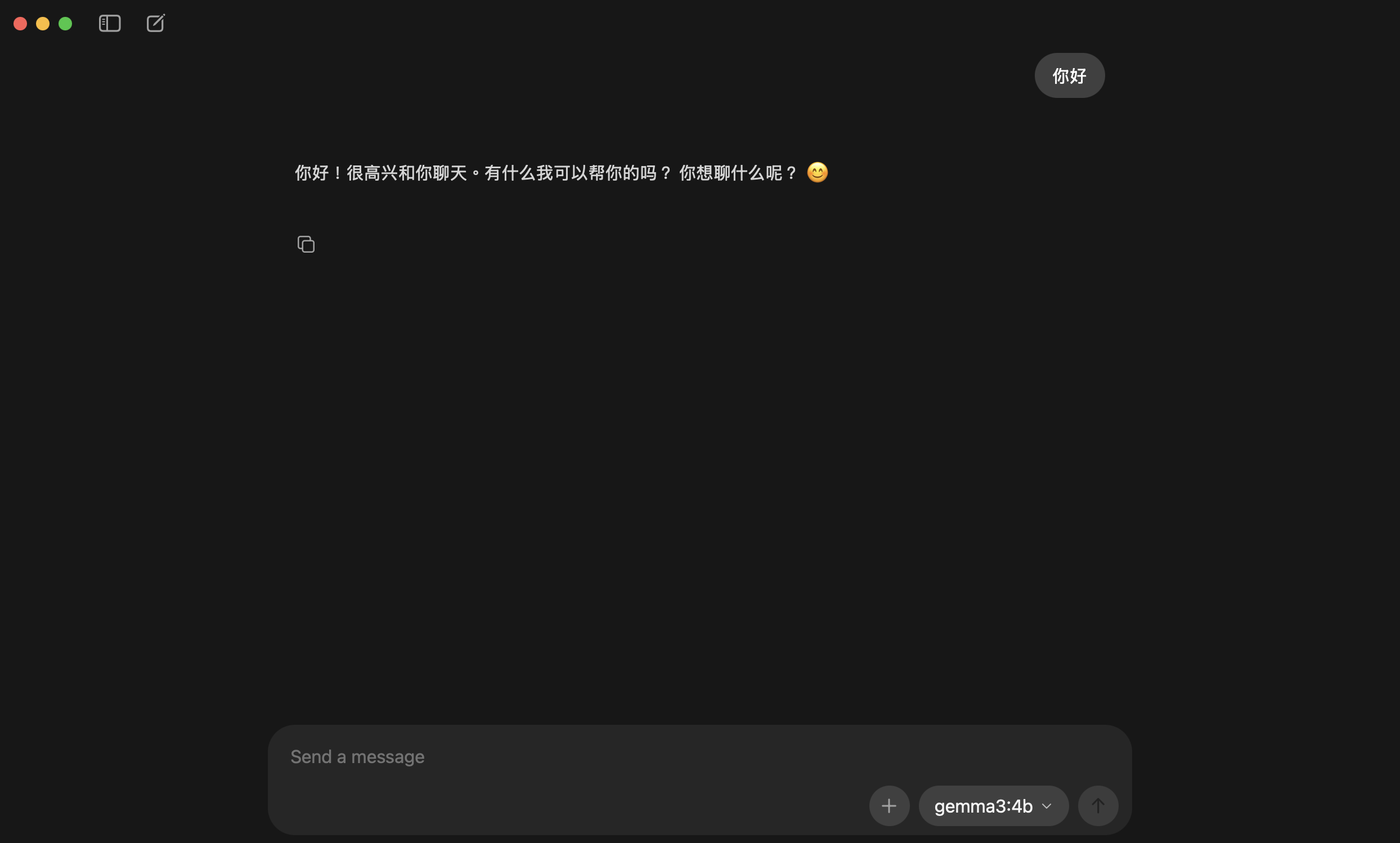
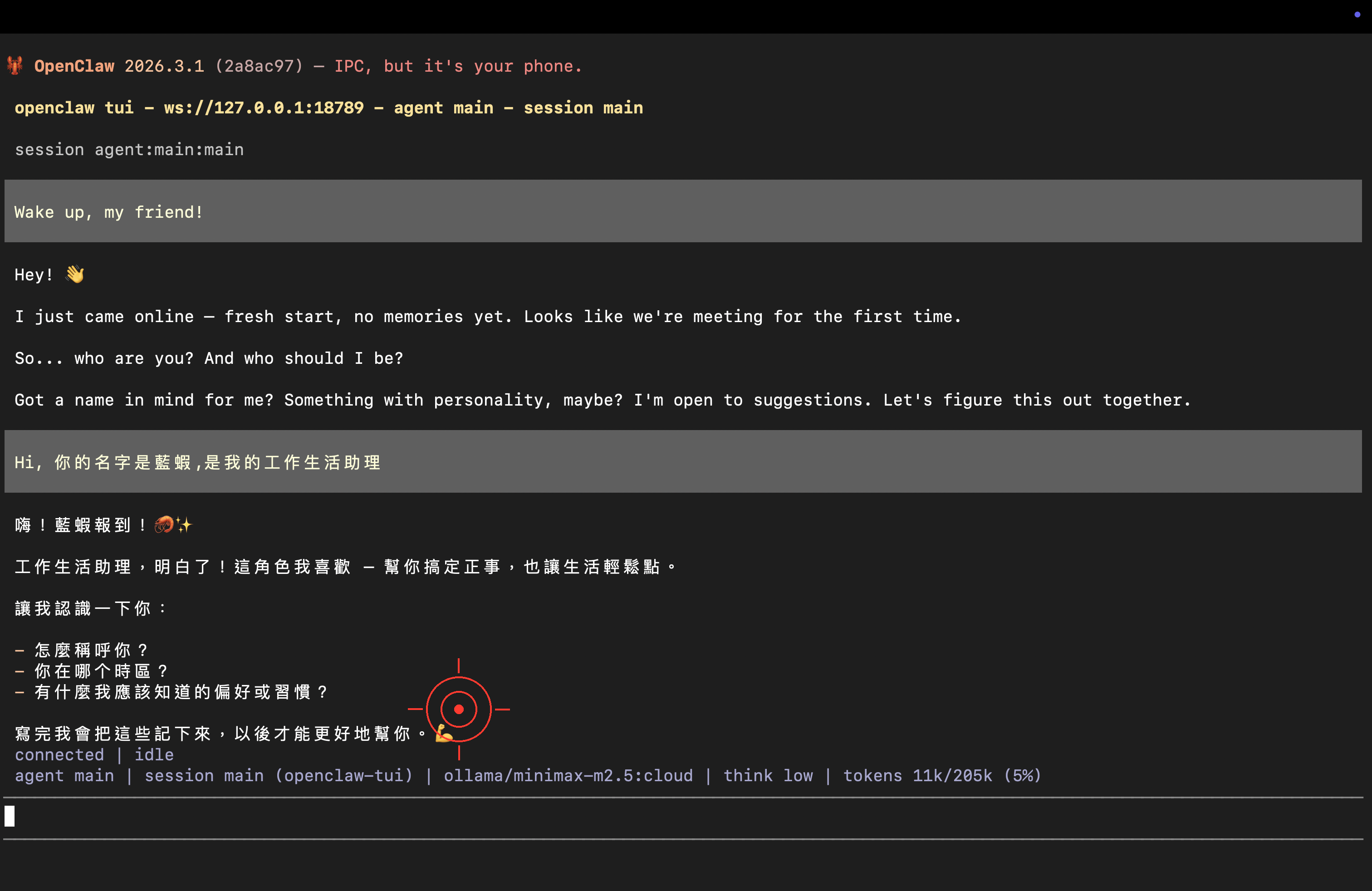
恭喜 🎉 你的龍蝦正式啟動!
<img src="/images/dock_head_s.png" alt="鴨編" width="24" style="vertical-align: middle;">如果模型回應是英文,直接告訴它:「請用繁體中文回覆」,它就會切換語言。
免費額度說明
Ollama 雲端模型有免費額度(官方說明)。查看用量:
- 前往 ollama.com/settings,用 Google 帳號登入
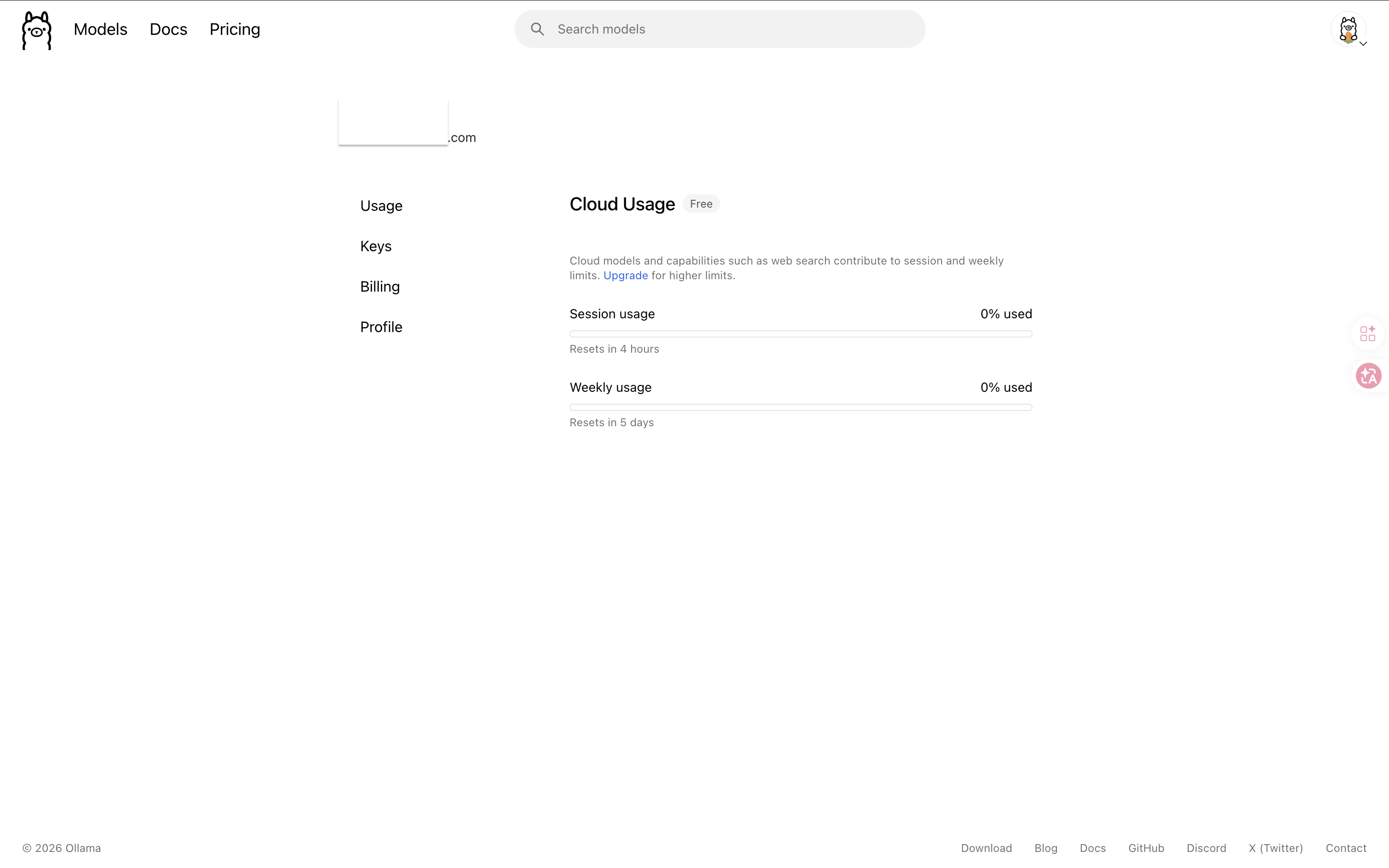
額度用完?可改用 Gemini Flash 雲端 API,或在本機下載開源模型(見下方補充)。
常見問題
🚨 OpenClaw 連不上 Ollama
# 確認 Ollama 有在運行
ollama ps
# 確認 API 正常
curl http://localhost:11434/api/tags確認系統工具列有 Ollama 圖示,如果沒有,重新打開 Ollama app。
🚨 模型回應很慢
用雲端模型(Cloud)不受本機規格影響;如果切換到本機模型才會有速度差異。
🚨 想換模型
重新執行 ollama launch openclaw 或到設定頁切換:
ollama launch openclaw --config補充:在本機下載開源模型(可選)
想完全離線、節省雲端額度,或純粹好奇?以下是快速說明。
確認規格(本機模型最低需 8 GB RAM):
| 你的配備 | 推薦模型 | 預期速度 |
|---|---|---|
| 8GB RAM,無 GPU | llama3.2:3b | 每秒 5-10 Token |
| 16GB RAM,Apple M1 | qwen2.5:7b | 每秒 15-25 Token |
| 32GB+ RAM,Apple M 系列 | qwen2.5:14b | 每秒 30+ Token |
# 下載(推薦中文使用者)
ollama pull qwen2.5:7b
# 測試
ollama run qwen2.5:7b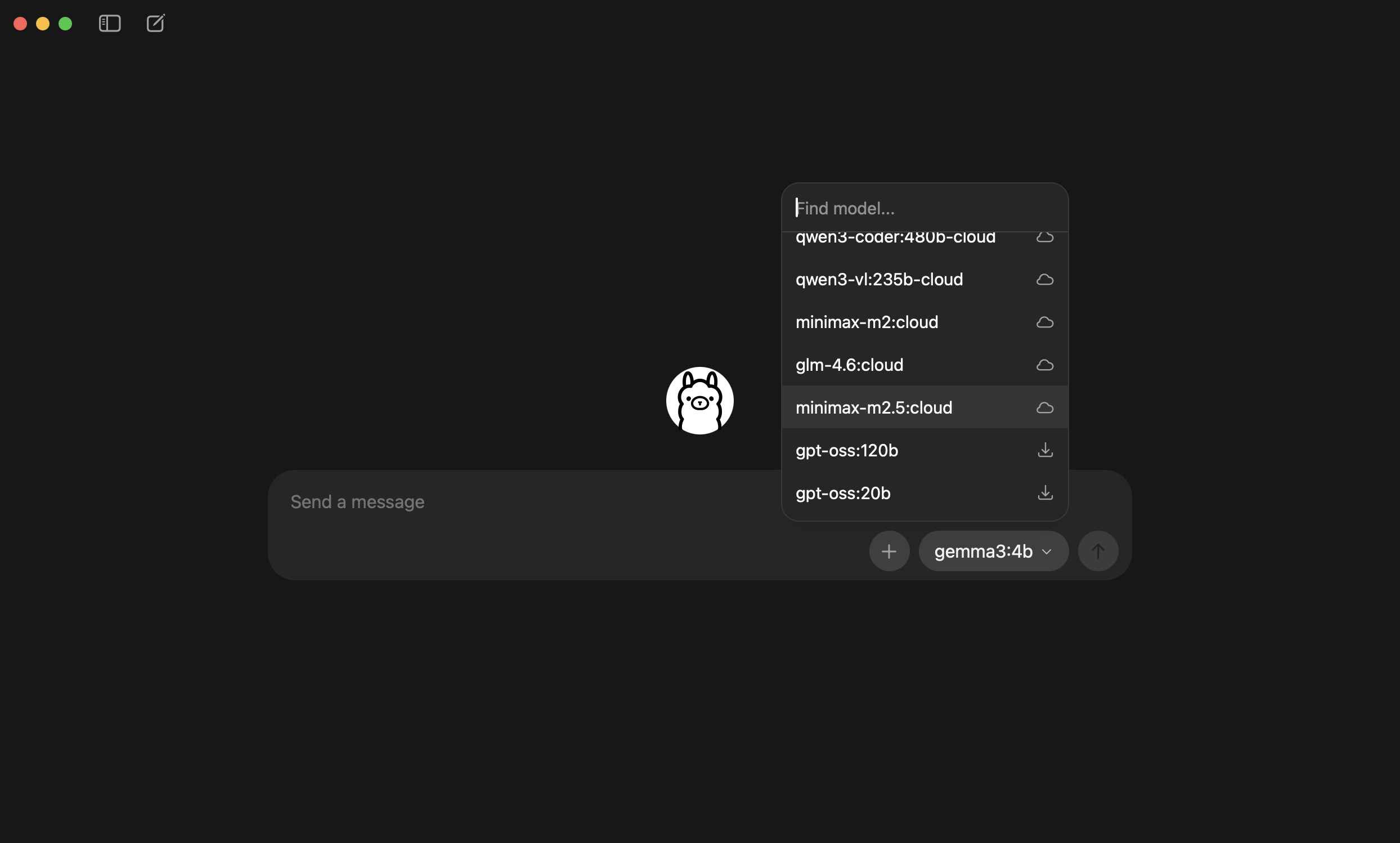
Apple Silicon(M1/M2/M3/M4)會自動啟用 GPU 加速,不需額外設定。
下一步
- ⚙️ 模型設定與切換
- 🧩 打造你的第一個 Skill
- 📱 串接 Telegram
有問題?到 首頁討論區 一起討論!
這篇文章對你有幫助嗎?
💬 問答區
卡關了?直接在這裡問,其他讀者和作者都能幫忙解答。
載入中...